


본 챕터의 가장 중요한 것은 routing 알고리즘과 프로토콜이다.
2. Routing Protocol

라우팅 프로토콜의 목표는 좋은 경로를 찾는 것이다(여기서 좋은 경로란, 최소한의 비용으로 가장 빠르게 가장 낮은 혼잡도를 의미한다).

그래프를 나타낼 때는 G로 표현하고 N과 E의 집합으로 나타낸다.
여기서 N은 Node의 약자로 라우터의 집합을 의미하고, E는 Edge의 약자로 링크의 집합을 의미한다.

c(x, x')라고 쓰면 x에서 x' 까지 가는 링크의 코스트를 의미한다.

라우팅 알고리즘은 어떻게 나눠지는가를 알아보자.
먼저 정보가 global 한지 아니면 decentrallized(local과 같은 의미인듯) 한지에 따라 구분된다.
· 정보가 global 한 경우
모든 라우터가 토폴로지와 링크 코스트 정보를 완벽하게 알고 있을 때
link state 알고리즘이다.
그리고 이 link state 알고리즘의 대표 주자가 다익스트라 알고리즘이다.
· decentralized한 경우
라우터가 물리적으로 연결되어있는 이웃 노드와 그 이웃의 링크 코스트 정보만을 알고있을 때
반복적으로 메시지 체인지를 해서 순차적으로 정보를 업데이트 해서 완성시킨 다음 동작한다.
distance vector 알고리즘이다. 다이나믹 프로그래밍, 벨만 포드 방정식을 사용해서 구현한다.
static(정적) 한지와 dynamic(동적)인지로도 나뉜다.
즉, 경로가 천천히 바뀌는지 빠르게 바뀌는지이다.

link-state 라우팅 알고리즘에는 대표적으로 다익스트라 알고리즘이 있다.
다익스트라 알고리즘은 모든 노드들의 링크 코스트를 알고 있다는 가정하에 forwarding table이 만들어진다.
내가 source node인데 k 개의 destination node들과 연결될 때, 최소 비용의 경로를 알려면 k번의 루프를 돌면 알 수 있다.
notation
C(x, y) : 노드 x부터 y까지의 링크 코스트
D(v) : 출발지에서 목적지까지의 경로의 코스트
P(v) : 출발지에서 v까지의 도달할 수 있는 경로
N' : 최소 비용 경로로 정의된 노드의 집합

즉, 다익스트라 알고리즘은 12번째 줄이 핵심이다.
D(v) = min(D(v), D(w)+c(w,v))
내가 출발지에서 v까지 도달하는데 total cost는 지금까지 계산된 것과 새로운 경로로 우회해서 간 경로 중 코스트가 가장 작은 값이 저장되는 것이다.
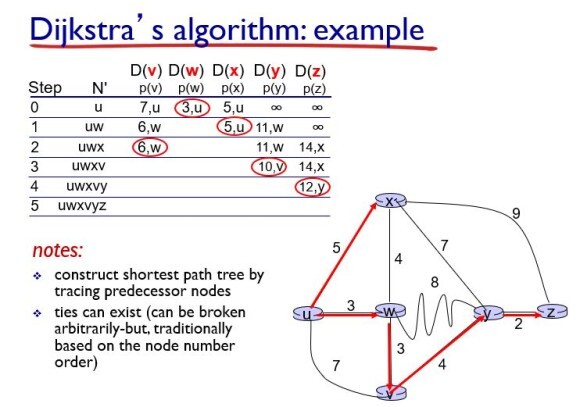
예시를 봐보자. source node가 u라고 해보자.
맨 먼저 step 0에서 v로 갔을 때의 비용은 7, w는 3, x는 5가 들고, y와 z는 현재 바로 갈 수 없으므로 무한대로 설정한다.
step 0에서 제일 minimum한 노드를 찾는다((3, u) 즉, node w).
그럼 다음 step에서 minimum한 노드 w에서 출발해서 기존의 값들이 update 될 수 있는지를 계산한다. D(v)의 경우 원래 코스트가 7이였지만, uwv로 가면 6의 코스트로 도달할 수 있으므로 업데이트 해준다. 이 방식을 반복적으로 수행한다.
즉 6개의 노드가 있으므로 6번의 iteration을 통해 minimum cost 값들을 모두 계산할 수 있다.

다익스트라 알고리즘은 O(n2)의 복잡도가 일어나지만 O(nlogn)까지 줄일 수 있다.
다익스트라 라우팅의 단점은 특정 라우터에 트래픽이 몰려서 congestion이 발생하게 된다.

Distance vector 알고리즘에는 대표적으로 벨만 포드 방정식이 있다.
Distance vector algorithm의 핵심은
dx(y) = min{c(x,v)+dy(y)}
즉, 내가 x에서 출발해서 y까지 가고 싶을 때, x에서 갈 수 있는 노드의 코스트와 그 코스트에서 최종적으로 y까지 갔을 때의 경로의 합 중 가장 작은 값이 최소한의 비용으로 갈 수 있는 경로라는 것이다.

마찬가지로 예시를 봐보자.
source node가 u, destination node가 z라고 했을 때, u에서 갈 수 있는 노드는 n, x, w가 있다.
dv(z)는 vxyz로 가면 각각 2 + 1 + 2 = 5가 되고, dx(z) 는 xyz로 1+2=3, dw(z)는 wyz = 3이 된다.
그러면 최종적으로 du(z) 는 min{c(u,v) + dv(z), c(u,x) + dx(z), c(u,w) + dw(z)} = {7, 4, 8} = 4가 된다.
즉, Distance vector 알고리즘은 인접한 노드들끼리 relay로 코스트를 계산해서 최소 비용 경로를 찾는 것이다.

Distance vector 알고리즘은 3가지 특성을 가지고 있다.
- 반복적이다.
- 비동기적이다.
- 분산적으로 처리된다.
각각의 라우터가 locally하고 싱크를 맞춰줄 필요가 없다.
1. 각각의 노드가 인접한 노드에게 local link cost가 바꼈다는 메시지를 받는 것을 기다린다.
2. 인접한 노드에게 받은 정보를 기반으로 재계산을 한다. 이때, Distance Vector가 바뀌지 않으면 무시한다.
3. 만약 Distance Vector가 변하면 수정된 값을 인접한 노드들에게 알려준다.
이 과정을 반복적으로 수행한다.

제일 왼쪽의 table은 아직 정보 공유가 되지 않아 자신의 경로 비용만 알고 있다. 그다음, 각 노드들이 자신의 table 정보를 공유해서 업데이트를 해준다. 이 때, 가운데 위(node x의 second table)를 보면 원래 x에서 z로 가는데 7의 코스트가 들었는데, xyz의 경로로 가면 3의 코스트로 갈 수 있으므로 7 -> 3으로 업데이트가 되고, 이 정보를 다시 다른 노드들에게 알려준다.
이 과정을 반복적으로 수행한다.
즉, 각 라우터마다 distribute하게, 반복을 통해, 비동기적으로 table이 업데이트가 된다.


Distance Vector 알고리즘에서 link cost 값이 변할 때, 특정 경로의 비용이 감소하게 됬을 때는 큰 문제가 없는데, 특정 경로의 비용이 크게 증가하였을 때 문제가 발생한다.
만약 yx 경로의 코스트가 4에서 60으로 증가하게 되었다고 해보자.
그러면 y가 x로 패킷을 보낼려면 yzx로 보내야 한다. 그런데 z 입장에서는 y에게 yx경로의 코스트가 60이 되었다는 것을 직접 돌려보기 전에는 업데이트가 되지 않는다. 그래서 y는 z에게 패킷을 보내고 z는 이 패킷을 x에게 보내는 것이 아닌 다시 y에게 보내게 된다.

link-state와 distance vector 알고리즘을 비교해보자.
메시지 복잡도는
LS의 경우 n개의 노드와 E개의 링크가 있을 때, O(nE)의 복잡도를 가진다.
DV의 경우 상황에 따라 다양하게 나온다.
수렴 속도는
LS의 경우 O(n2)이다. oscillation이 발생할 수 있다.
DV의 경우 상황에 따라 다양하게 나온다. count-to-infinity 문제가 발생할 수 있다.
robustness
LS의 경우 노드가 링크 코스트를 잘못 broadcast할 수 있다. 하지만 각 노드들의 자신의 table을 계산하기 때문에 큰 문제가 되지 않는다.
DV의 경우 잘못된 경로 코스트가 퍼지면 전체 네트워크에 문제가 생길 수 있다.
'Study > 네트워크' 카테고리의 다른 글
| 5. Network Layer: Control Plane(3) (0) | 2023.06.14 |
|---|---|
| 5. Network Layer: Control Plane(2) (0) | 2023.06.14 |
| 4. Network Layer (Data Plane) (2) (1) | 2023.06.14 |
| 4. Network Layer (Data Plane) (1) (6) | 2023.06.14 |
| 3. Transport Layer (3) (1) | 2023.06.14 |