

출처 : https://www.youtube.com/watch?v=r1JVA7yOPAM&list=PLBrGAFAIyf5rby7QylRc6JxU5lzQ9c4tN&index=9

굉장히 다양한 기본 스케줄링 알고리즘이 존재한다.

FCFS(First-Come-First-Service)
선착순 알고리즘 : 먼저 오는 프로세스에게 먼저 프로세서를 할당해준다.
- Non-preemptive scheduling(비선점 스케줄링 : 누구도 내 것을 뺏을 수 없음)
- 스케줄링 기준
- 도착 시간 (ready queue 도착한 기준)
- 먼저 도착한 프로세스를 먼저 처리
- 자원을 효율적으로 사용 가능
- High resource utilization = scheduling overhead가 낮다, CPU의 효용이 높다. (그냥 오는 순서대로 프로세서를 할당해주면 되므로 스케줄링에 대한 오버헤드가 굉장히 작고 프로세서가 계속 일을 할 수 있다는 장점이 있다.)
- Batch system(일괄처리 시스템)에 적합, interactive system(대화형 시스템)에 부적합 (응답을 빠르게 해주는 것보다는 쓰루풋을 향상시키는 것이 더 좋음)
- 단점
- Convoy effect
- 하나의 수행시간이 긴 프로세스에 의해 다른 프로세스들이 긴 대기시간을 갖게 되는 현상(대기 시간 >> 실행시간) (ex. 나는 2초만 쓰면 되는 작업인데 먼저 쓰고 있는 애가 1시간이 걸리면 나는 1시간 2초 뒤에 결과를 받음)
- 긴 평균 응답시간 (response time) : 내가 작업을 요청했는데 언제 결과를 받을지 모름
- Convoy effect

프로세스들이 순서대로 프로세서에 들어가고, 작업을 마치면 순서대로 나가게 된다.

예시를 봐보자.
프로세스는 P1~P5가 있다.
맨 처음 P1은 0초에 프로세서에 도착해서 3초의 Burst time(실행시간)을 가진다. 맨 처음 도착했을 때 프로세서는 비어있으므로 0초에 waiting time(대기 시간)을 가지고 Turnaround time(작업을 요청해서 끝날 때까지의 시간)은 3초가 걸린다. 정규화된 TT(TT / BT, 체감 TT, 1보다 클수록 오래기달렸다는 뜻)는 3 / 3 = 1 가된다.
3초 뒤에 ready queue에는 P2(1초에 도착)과 P3(3초에 도착)가 들어있다. P2가 먼저 ready queue에 들어가있으므로 P2가 먼저 프로세서를 할당받는다. 1초에 도착해서 3초에 작업을 시작하므로 2초의 waiting time을 가진다. TT는 2초를 기다리고 7초 동안 실행을 했으므로 9초이다. NTT는 9 / 7 = 1.3 이 된다.
10초에 P2가 완료되었을 때 ready queue에는 P3(3초), P4(5초), P5(6초)가 들어있다. P3가 가장 먼저 ready queue에 들어갔으므로 P3가 먼저 프로세서를 할당받는다. 3초에 도착해서 10초에 작업을 시작하므로 7초의 WT를 가진다. TT는 7초를 디라고 2초동안 실행을 하므로 9초이다. NTT는 9 / 2 = 4.5 가 된다.
12초에 P3가 완료되었을 때 ready queue에는 P4(5초), P5(6초)가 들어있다. P4가 먼저 ready queue에 들어왔으므로 P4가 프로세서를 할당받는다. 5초에 도착해서 12초에 작업을 시작하므로 7초의 WT를 가진다. TT는 7초 + 5초 = 12초가 되고, NTT = 12 / 5 = 2.4 가 된다.
마지막으로 17초에 P5(6초)가 프로세서를 할당받는다. 6초에 도착해서 17초에 작업을 시작하므로 11초의 WT를 가진다. TT = 11 + 3 = 14초, NTT = 14 / 3 = 4.7 이 된다.
정리하면 다음과 같다.

보면 P3 때문에 뒤에있는 애들이 굉장히 오래 기다리게 된다. 이것이 Convoy effect이다.

RR (Round-Robin)
제한 시간을 두고 돌아가면서 쓰자.
- Preemptive scheduling (선점 스케줄링 : 누가 와서 내 것을 빼앗을 수 있음)
- 스케줄링 기준
- 도착 시간 (ready queue 기준)
- 먼저 도착한 프로세스를 먼저 처리
- 자원 사용 제한 시간 (time quantum) 이 있음
- System parameter
- 프로세스는 할당된 시간이 지나면 자원 반납
- Timer-runout
- 장점 : 특정 프로세스의 자원 독점 (monopoly) 방지
- 단점 : Context switch overhead가 큼 (계속 돌아가면서 사용해야 하기 때문에)
- 대화형(Interactive system), 시분할 시스템(Time-sharing system)에 적합(응답이 빨라야하는 시스템)

- Round-Robin 알고리즘은 Time quantum(자원 사용 제한 시간)이 시스템 성능을 결정하는 핵심 요소이다.
- Time quantum이 Very large (infinite) = FCFS
- Time quantum이 Very small time quantum (0의 수렴) = processor sharing (프로세서를 동시에 쓰는 느낌을 받음)
- 사용자는 모든 프로세스가 각각의 프로세서 위에서 실행되는 것처럼 느낌
- 체감 프로세서 속도 = 실제 프로세서 성능의 1/n
- High context switch overhead
- 사용자는 모든 프로세스가 각각의 프로세서 위에서 실행되는 것처럼 느낌

이전에 FCFS는 프로세스가 프로세서에 들어가고 작업이 끝나면 바로 완료가 되서 나가는 action만 있었는데, RR은 Timer-runout이라는 action 이 추가가 되서 다시 ready queue의 맨 뒤에 가서 줄을 서게 된다.

RR의 예시를 봐보자. Arrival time과 Burst time은 이전 예시와 동일하고, Time quantum은 2초라고 가정한다.
0초 ~ 2초
제일 먼저 P1(AT : 0초, BT=3초)가 ready queue에 들어온다. 이때 프로세서는 비어있으므로 P1은 바로 작업을 실행한다. 이때 P1이 작업을 완료하려면 3초가 필요한데 time quantum이 2초이므로 2초 동안만 작업을 하고 다시 ready queue에 들어간다. 이때 P1(BT : 1초)
2초 ~ 4초
P1(AT : 0초, BT : 1초)이 작업을 진행하는 사이 P2(AT : 1초, BT : 7초)가 ready queue에 들어왔다. 즉, ready queue에는 P2, P1 순으로 들어가 있다. 따라서 다음에는 P2가 프로세서를 할당받고 P1이 ready queue의 맨 앞으로 당겨진다. P2가 작업을 완료하려면 7초가 필요한데 time quantum이 2초이므로 2초 동안만 작업하고 다시 ready queue에 들어간다. 이때 P2(BT : 5초)
4초 ~ 5초
P2가 작업을 진행하는 사이 P3(AT : 3초, BT : 2초)가 ready queue에 들어왔다. 즉, ready queue에는 P1, P3, P2 순으로 들어가 있다. 따라서 다음에는 다시 P1(BT : 1초)이 프로세서를 할당받고 ready queue : P3, P2 순으로 줄을 서게 된다. P1의 남은 작업은 1초 밖에 안걸리므로 1초 뒤에 작업을 끝마치게 된다. P1은 앞에 P2 한 번만 기다렸으므로 P1의 WT = 2초가 되고, TT = 2초 + 3초 = 5초, NTT = 5 / 3 = 1.7 이 된다.
5초 ~ 7초
P1이 작업을 끝마쳤을 때, P4(AT : 5초, BT : 5초)가 ready queue에 들어왔다. 즉, ready queue에는 P3, P2, P4 순으로 줄을 서고 있으므로, P3가 프로세서를 할당받고 ready queue에는 P2, P4 순으로 줄을 서게 된다. P3의 BT = 2초인데, time quantum = 2초 이므로 P3는 일을 끝마치게 된다. P3는 3초에 ready queue에 들어와 5초에 프로세서를 할당받았으므로 WT = 2초, TT = 2초(WT) + 2초(BT) = 4초, NTT = 4초 / 2초 = 2 가 된다.
7초 ~ 9초
P3가 작업을 진행하는 사이 P5(AT : 6초, BT : 3초)가 ready queue에 들어왔다. 즉, ready queue에는 P2, P4, P5 순으로 줄을 서고 있으므로, P2(BT : 5초)가 프로세서를 할당받고, ready queue에는 P4, P5 순으로 줄을 서게 된다. P2는 다시 2초동안 일을 진행하고 아직 BT = 3초가 남았으므로, 다시 ready queue의 맨 뒤로 줄을 서게 된다.
9초 ~ 11초
즉, ready queue에는 P4(BT : 5초), P5(BT : 3초), P2(BT : 3초)가 줄을 서고 있으므로, P4(BT : 3초)가 프로세서를 할당받고, ready queue에는 P5, P2가 줄을 서고 있다. P4는 2초 동안 일을 진행하고 BT = 3초가 남았으므로 다시 ready queue의 맨 뒤로 줄을 서게 된다.
11초 ~ 13초
ready queue에는 P5(BT : 3초), P2(BT : 3초), P4(BT : 3초) 순으로 줄을 서고 있으므로, P5(BT : 3초)가 프로세서를 할당받고, ready queue에는 P2, P4 순으로 줄을 서고 있다. P5는 2초 동안 일을 진행하고 BT = 1초가 남았으므로 다시 ready queue의 맨 뒤로 줄을 서게 된다.
13초 ~ 15초
ready queue에는 P2(BT : 3초), P4(BT : 3초), P5(BT : 1초) 순으로 줄을 서고 있으므로, P2(BT : 3초)가 프로세서를 할당받고, ready queue에는 P4, P5 순으로 줄을 서고 있다. P2는 2초 동안 일을 진행하고, BT = 1초가 남았으므로 다시 ready queue의 맨 뒤로 줄을 서게 된다.
15 ~ 17초
ready queue에는 P4(BT : 3초), P5(BT : 1초), P2(BT : 1초) 순으로 줄을 서고 있으므로, P4(BT : 3초)가 프로세서를 할당받고, ready queue에는 P5, P2 순으로 줄을 서고 있다. P4는 2초 동안 일을 진행하고, BT = 1초가 남았으므로 다시 ready queue의 맨 뒤로 줄을 서게 된다.
17 ~ 18초
ready queue에는 P5(BT : 1초), P2(BT : 1초), P4(BT : 1초) 순으로 줄을 서고 있으므로, P5가 프로세서를 할당받고, ready queue에는 P2, P4 순으로 줄을 서고 있다. P5의 남은 작업은 1초만 남았으므로 1초 뒤인 18초에 작업을 끝마치고 나오게 된다. P5가 ready queue에서 대기한 시간은 6초 ~ 11초 (during 5초), 13초 ~ 17초(during 4초) 이므로 WT = 5 + 4 = 9초가 되고, TT = 9초(WT) + 3초(BT) = 12초, NTT = 12 / 3 = 4 가 된다.
18초 ~ 19초
ready queue에는 P2(BT : 1초), P4(BT : 1초) 순으로 줄을 서고 있으므로, P2가 프로세서를 할당받고, ready queue에는 P4 순으로 줄을 서고 있다. P2의 남은 작업은 1초가 남았으므로 1초 뒤인 19초에 작업을 끝마치고 나오게 된다. P2는 1초에 ready queue에 들어와서 19초에 작업을 끝마쳤으므로 TT = 18초, WT(ready queue에서 대기한 시간) = 18초(TT) - 7초(BT) = 11초, NTT = 18 / 7 = 2.6이 된다.
19 ~ 20초
ready queue에는 P4(BT : 1초) 만 남았으므로 P4가 프로세서를 할당받는다. P4의 남은 작업은 1초만 남았으므로 1초 뒤인 20초에 작업을 끝마치게 된다. P4는 5초에 ready queue에 들어와서 20초에 작업을 완료했으므로 TT = 15초, WT = 15초(TT) - 5초(BT) = 10초, NTT = 15 / 5 = 3 이 된다.
정리하면 아래 그림과 같다.


response time은 중간의 최초의 결과값(output)이 나오는 시간이다. 그런데 RR의 경우 output이 중간에 없으므로 TT = response time이 된다.
따라서 평균 응답시간 (Average response time) = (5 + 18 + 4 + 15 + 12) 초 / 5 개 = 54 초 / 5 개 = 10.8 초 이 된다.
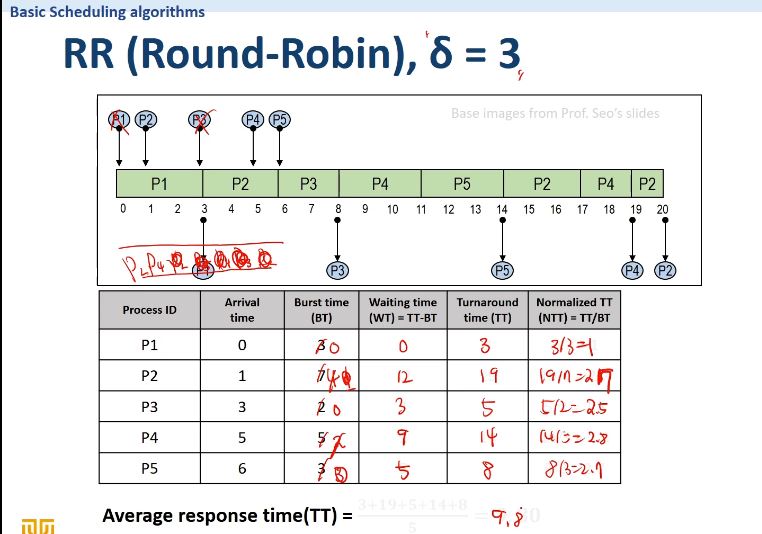
Time quantum 을 3초로 설정하면 위 그림과 같다.
평균 응답시간이 2초였을 때보다 줄어든 것을 확인할 수 있다. 즉, Time quantum에 따라 시스템 성능에 변화가 생긴다는 것을 확인할 수 있다.
'Study > 운영체제' 카테고리의 다른 글
| 5. 프로세스 스케줄링 (4) - MLQ, MFQ (0) | 2023.11.11 |
|---|---|
| 5. 프로세스 스케줄링 (3) - SPN, SRTN, HRRN (0) | 2023.11.09 |
| 5. 프로세스 스케줄링 (1) (0) | 2023.11.06 |
| 4. 스레드 관리 (0) | 2023.11.03 |
| 3. 프로세스 관리 (2) (0) | 2023.11.03 |