

- Principles of network application

이 챕터에서는 Application Protocol이 구성이 되는지, 어떤 패러다임에 의해서 만들어졌는지, 다양한 Application Protocol에 무엇이 있는지를 배우는 것을 목표로 한다.
TCP/IP 네트워크 프로토콜 스택에서 가장 상위 레이어를 담당하고 있는 놈이 Application Layer이다. Application layer는 그 이름에 걸맞게 end system 들에게 여러가지 서비스를 제공하거나 제공 받는 부분을 책임진다.
즉, 이메일, 웹서핑같은 서비스를 제공하고 제공받기 위해서 어떤 형식으로 메시지를 주고 받아야 하는지의 프로토콜들이 모여있는 레이어이다.
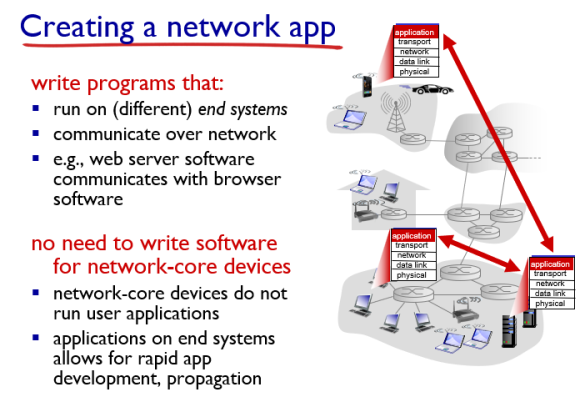
우리가 만든 App 프로그램은 모두 end system에서 동작한다. 그리고 app 프로그램을 네트워크를 통해 통신을 한다.
Application 프로그램은 오직 소켓을 해가지고 transport layer에 서비스에만 depend한다. 따라서 network core 파트는 신경쓰지 않아도 된다(스위치나 라우터가 어떻게 동작하는지 무시).
이럴 때의 장점은 오로지 Application Layer만 신경쓰면 되기 때문에 개발 속도가 빨라진다는 장점이 있다.
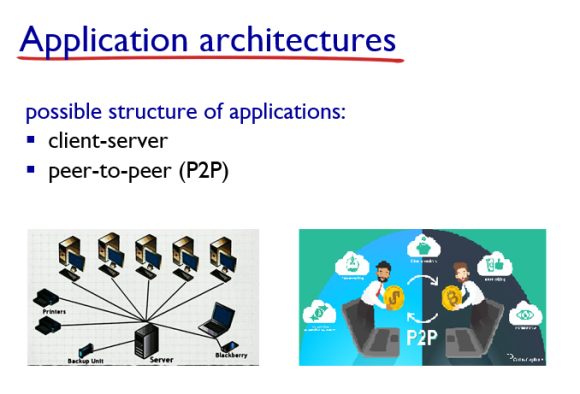
Application 아키텍처에는 2가지 구조가 있다.
· client-server 구조
· P2P 구조
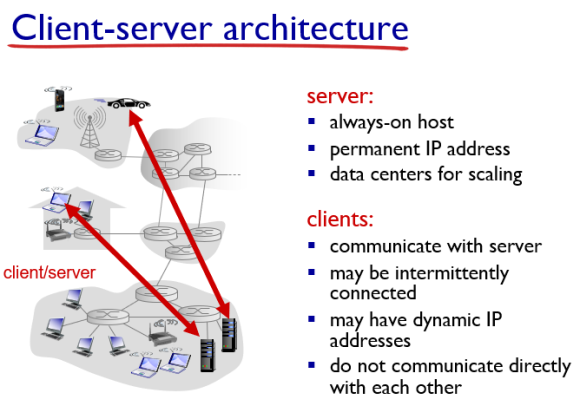
클라이언트-서버 구조는 고정된 IP 주소를 가진 서버(대용량 컴퓨터)와 동적으로 변화하는 IP 주소를 가진 클라이언트(랩탑, 핸드폰)이 랜선으로 연결되어있는 구조를 의미한다.
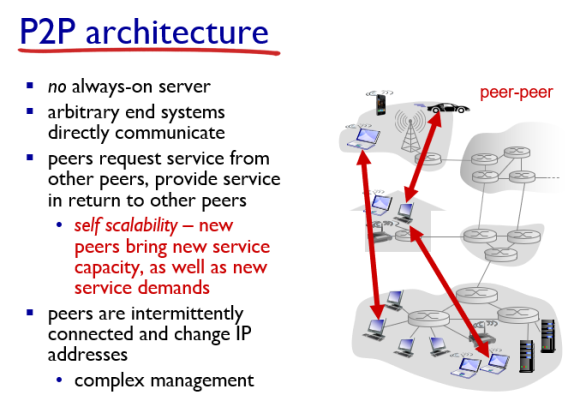
P2P 구조란 클라이언트끼리 연결되어있는 구조를 의미한다.
서버가 없이 애드혹으로 여러 클라이언트들이 모여서 작업을 하고, 어떤 요구 조건이 있으면 클라이언트가 되고 어떤 요구를 받으면 서버의 역할을 하는 구조이다.
확장성이 좋다는 특징이 있다.
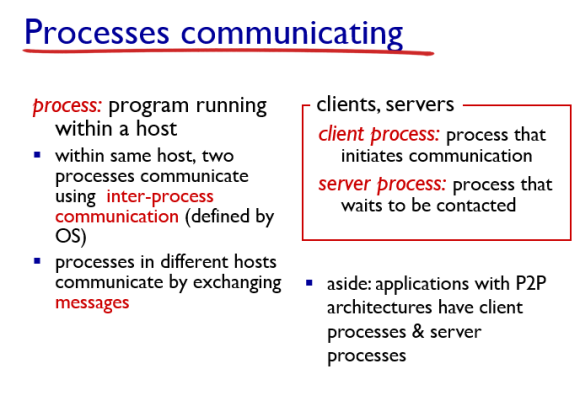
프로세스 커뮤니케이션이란 말 그대로 프로세스들끼리 통신하는 것을 의미한다.
프로세스란 하나의 호스트에서 동작하는 프로그램을 의미한다.
서로 다른 호스트에 있는 서로 다른 프로세스가 메세지를 통해서 통신하는 것이 네트워크의 주요 이슈이다.
클라이언트 프로세스는 통신을 개시하는 프로세스, 서버 프로세스는 해당 요청을 기다리고 받아드리는 프로세스를 말한다.
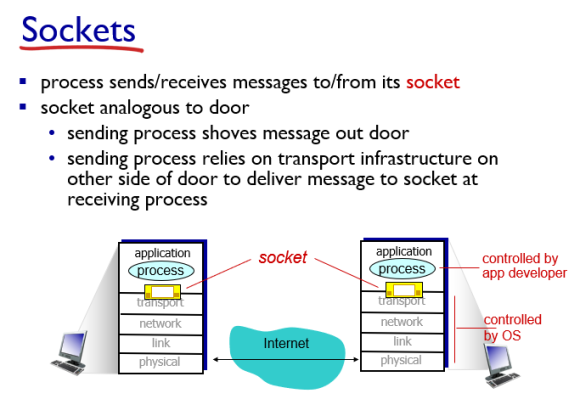
Application의 process들이 통신을 하는데 application layer의 application은 application layer에만 집중한다. 근데 이 application이 밑에 단(transport layer, network layer 등등)을 사용하고 싶을 때, 소켓을 사용해서 보내고 싶은 메시지를 전송한다. 즉, 소켓은 다른 layer로 메시지를 보내는 문과 같은 역할을 한다.
이때, application layer를 떠난 이후에 일은 application layer에서는 신경 쓰지 않는다.

서버의 입자에서 메시지를 받는데, 이 메시지가 누구의 프로세스에서 온 메시지인지를 구분해야 할 필요가 있다. 이때, 필요한 것이 identifier라고 한다. 이를 하기 위해서 호스트 디바이스는 IP 주소를 할당받는다.
하지만 호스트 디바이스에 IP 주소를 할당해주는 것만으로는 부족하다. 하나의 호스트에 여러 개의 프로세스들이 동작하기 때문이다.
각 호스트들은 IP 주소로 구분한다면, 하나의 호스트 안의 프로세스들은 어떻게 구분하는가? 바로 포트 넘버로 구분한다.
즉, Identifier는 IP 주소와 포트 넘버를 동시에 가지면서 이 메시지가 어느 호스트의 어느 프로세스인지를 구분할 수 있게 만든다.

Application layer의 프로토콜은 2가지로 나뉘어진다.
· Open Protocol(공짜 프로토콜)
HTTP, SMTP 등이 있다.
· Proprietary Protocol(사설 프로토콜 : 특정 회사가 특허권을 가진 프로토콜)
Skype가 있다.
2. Web and HTTP

우리가 웹페이지에 들어가면 한 페이지에 여러가지 오브젝트(그림, 오디오, 동영상 등등)들이 뜬다.
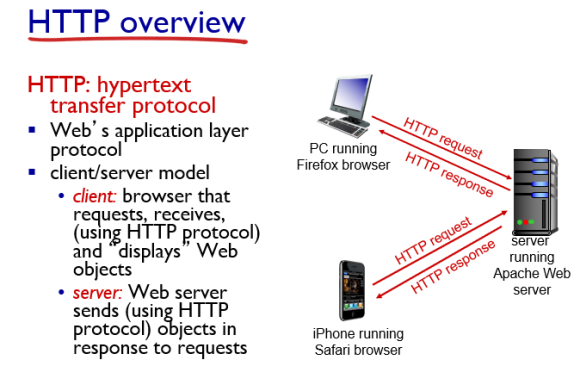
HTTP 프로토콜은 클라이언트가 서버에게 오브젝트를 요청하면 서버가 response 해주는 형식으로 동작한다.

HTTP는 TCP 프로토콜로 구성되어있다.
예를 들어, 클라이언트가 TCP로 서버에게 포트 번호 80을 통해 오브젝트를 요청을 한다. 그러면 서버는 해당 요청을 받고 반응을 한다.
HTTP는 인터넷이기 때문에 stateless로 구성이 되어있다. 즉, 클라이언트의 과거의 요청들은 신경을 쓰지 않고 오직 현재의 요청만을 신경쓴다.

HTTP 커넥션을 운영하는데 2가지 방식이 존재한다.
· non-persistent HTTP
맨 처음에는 무조건 non-persistent HTTP로 동작한다.
하나의 오브젝트를 전송하는데 한 커넥션을 열었다가 오브젝트를 가져오면 연결을 끊는다.
비효율적
· persistent HTTP
한번 커넥션을 연결하면 여러개의 오브젝트를 전송한다.
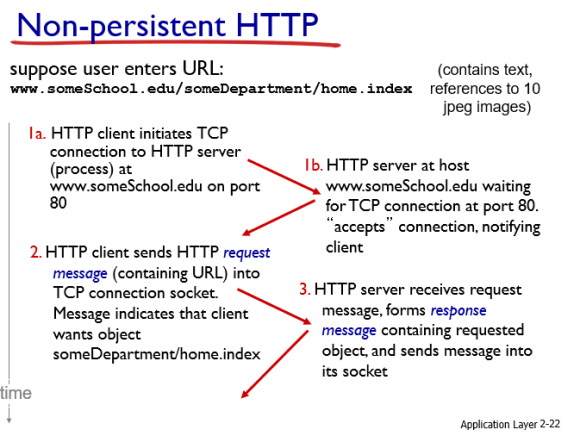

non-persistent HTTP
1번 : 클라이언트가 서버에게 connection을 요청한다.
1b번 : 서버가 connection을 승인해준다.
2번 : 클라이언트가 어떤 오브젝트를 원하는지가 담긴 메시지를 서버에게 전송한다.
3번 : 서버가 요청받은 오브젝트를 클라이언트에게 전송해준다.
4번 : 서버가 TCP connection을 끊는다.
5번 : 클라이언트가 object가 담긴 메시지를 받는다.
만약 10개의 오브젝트가 있다고 가정하면 1~5번 단계를 10번을 반복한다.
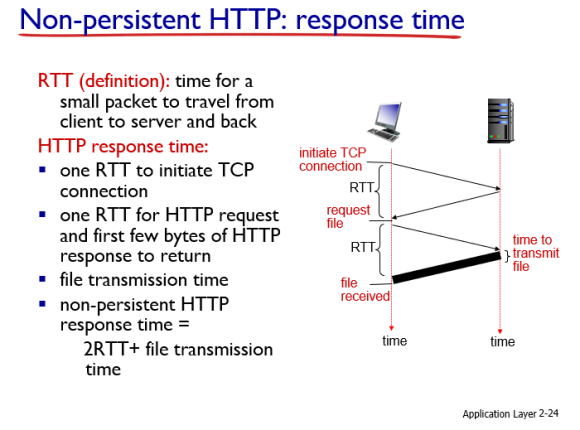
Round Trip Time(RTT) : 클라이언트에서 서버로 패킷이 전송되는데 걸리는 시간
Non-persistent HTTP에서 하나의 오브젝트를 전송하는데, TCP 연결을 initiate하는데 1 RTT, 실질적인 오브젝트가 전송되는데 걸리는 시간이 1 RTT와 파일 전송 시간이 걸려서 총 2RTT + file transmission time이 소모된다.

· Non-persistent HTTP
· 오브젝트 당 2 RTT 가 요구된다.
· 각 TCP 연결에 대해 OS 오버헤드가 발생한다.
· 병렬 TCP 커넥션을 할 수 있다. 즉, 여러 개의 TCP 커넥션을 통해 동시에 HTTP 요청을 할 수 있다.
· Persistent HTTP
· 서버가 리스폰스를 보내도 커넥션을 유지한다.
· 이후 같은 클라이언트와 서버는 열려있는 커넥션을 사용해서 요청 메시지를 전 송한다.
· 처음에 연결하는데 1RTT 그 뒤, 각 오브젝트에 대해서 1RTT 가 요구된다.
· 즉, 커넥션 하는 시간을 줄일 수 있다.

· 쿠키
HTTP는 기본적으로 stateless이기 때문에 상태를 기록하지 않지만, 기록이 필요한 경우가 있다. 이때 쿠키가 사용된다.
예를 들어, 내가 교보 문고 사이트에 접속해서 로그인도 하지않고 궁금한 책들을 보았다. 다음 날, 다시 교보 문고 사이트에 접속했을 때, 어제 본 책들과 유사한 책들을 추천해준다. 이것이 쿠키가 있기 때문에 가능한 일이다.
쿠키는 웹 사이트에 접속할 때 웹 사이트가 있는 서버에 의해 사용자의 컴퓨터에 저장되는 정보를 뜻한다.(서버에 저장되는 경우는 세션)
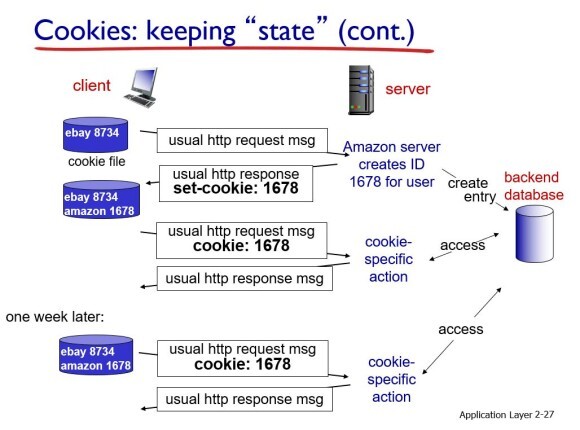
클라이언트의 IP Address는 고정이 되어있다. 내가 이전에 이베이를 방문했다. 그러면 내가 이베이를 접속했다는 기록이 쿠키로 남아있다. 그 뒤, 내가 아마존에 접속하면 아마존 서버에 http 프로토콜로 메시지를 보낼때, 나의 IP 주소, 포트 넘버를 포함해서 메시지를 전송한다. 아마존 서버는 자기가 모르는 IP address의 요청이 들어오면 거기에 고유의 ID 번호를 붙여준다. 그 뒤, 서버가 클라이언트에게 response 메시지를 보낼 때, 그 쿠기 번호를 넣어서 보낸다. 또한 데이터베이스에 IP address 등 관련된 정보를 저장한다. 쿠키 그러면 클라이언트에도 해당 쿠키 번호가 들어가 있게 된다. 그 뒤, 내가 아마존에서 여러 책들을 구경을 했다. 그러면 그 기록들이 데이터베이스에 기록이 되어지게 된다.
그리고 다음 주에 내가 다시 아마존에 접속하게 되면 나의 쿠키 번호를 통해서 저번 주에 왔던 너라는 것을 알고 전에 봤던 책과 유사한 책들을 추천해주게 된다.
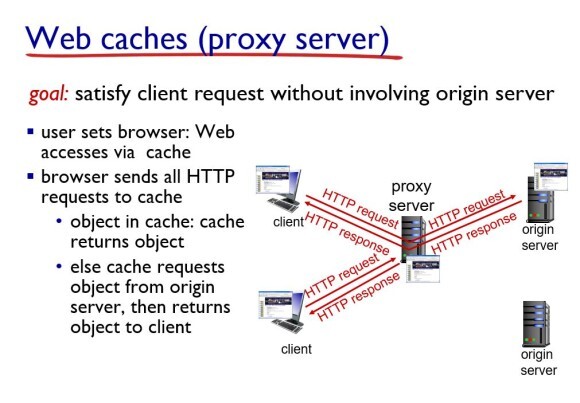
웹 캐시(프록시 서버)
오리지날 서버에 접속할 필요 없이 가까이에 있는 프록시 서버에만 접속해서 요청한 메시지를 받을 수 있기 때문에 리스폰스 시간을 줄여서 속도를 굉장히 증가시켜 주고 네트워크의 트래픽을 줄여준다.
예를 들어, 내가 넷플릭스에서 영화를 한편 본다고 해보자. 내가 대한민국에서 맨 처음 해당 영상을 본 사람이여서 대한민국 프록시 서버에 해당 영상이 없다면 어쩔 수 없이 미국에 있는 서버에 접속해야 한다. 그리고 이때 해당 영화가 프록시 서버에 저장된다. 그 뒤, 다음 사람부터는 해당 영화를 볼 때 미국에 오리지날 서버에 접속할 필요없이 대한민국에 있는 프록시 서버에만 접속하면 해당 영상을 볼 수 있게된다.
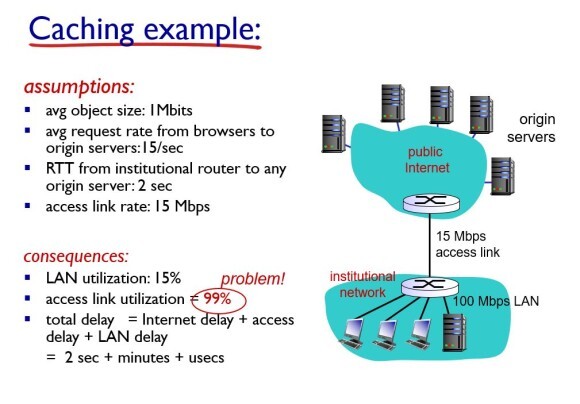
예시를 봐보자.
오브젝트들의 평균 사이즈가 1Mbits, 매초당 15개씩 요청이 된다. 위에 있는 라우터에서 오리지날 서버에 액세스하는데 2초가 걸리고 access link는 15Mbps의 링크이고, 밑의 LAN은 100Mbps라고 가정해보자. 밑의 LAN이 access link와 커넥션 되어있기 때문에 여기가 보틀넥이다. 오브젝트 사이즈가 1Mbits고 초당 15개가 생성되므로 액세스 링크가 거의 100% 사용된다. 그렇게 때문에 큐잉 딜레이가 기하급수적으로 증가한다. 해당 엑세스 링크를 통과하는데 수 분까지 걸린다.

그렇다면 단순 무식하게 액세스 링크 사이즈가 작으니까 링크 사이즈를 키워보자. 링크 사이즈를 10배 증가시키면 큐잉 딜레이는 확실히 감소하게 될테니 수 분 걸리던 것이 밀리세컨드로 줄어들게 된다. 그런데 문제는 저 액세스 링크를 확장하는데 돈이 어마어마하게 든다.(한국에서 미국으로 링크를 깐다고 생각해보자. 태평양 길이만큼 케이블을 깔아야된다.)
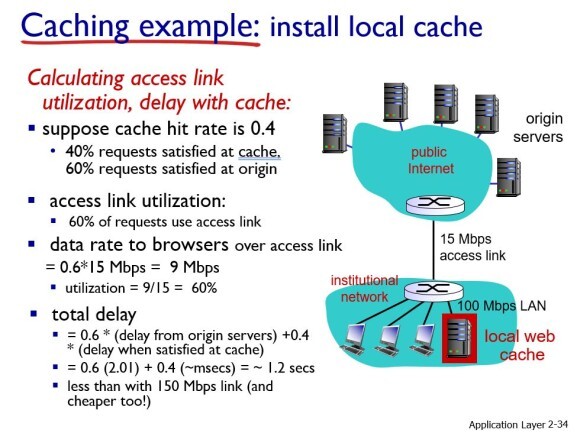
이번에는 로컬 웹 캐시를 설치해보자.
오브젝트의 40%는 웹 캐시에서 처리가능하고 60%는 오리지날 서버에 요청해야 된다고 가정해보자. 그러면 액세스 링크는 60%만 활용하면 된다. 그러면 최종적으로 딜레이를 계산해봤을 때, 라우터에서 오리지날 서버로 접속하는데 0.6 * 2초가 걸리고 로컬내에서 접속하는건 거의 밀리세컨드이므로 무시하면 최종적으로 약 1.2초가 걸리므로 액세스 링크를 확장시켰을 때의 2초보다 더 적은 시간이 걸리게 된다. 그리고 웹 캐시를 설치하는건 액세스 링크를 확장하는 거에 비하면 굉장히 싸게 먹힌다.
'Study > 네트워크' 카테고리의 다른 글
| 3. Transport Layer (2) (0) | 2023.06.14 |
|---|---|
| 3. Transport Layer (1) (0) | 2023.06.14 |
| 2. Application Layer (3) (0) | 2023.06.14 |
| 2. Application Layer (2) (0) | 2023.06.14 |
| 1. Introduction (0) | 2023.06.14 |