

3.5 Connection-Oriented Transport: TCP
(1) TCP Overview

· TCP는 point to point 프로토콜이다.
(point-to-point란 1대 1로 컴퓨터를 연결하는 프로토콜을 의미한다.)
· reliable하고 데이터들이 순서대로 들어온다.
· 파이프라인으로 전송하고, window size를 조절해서 혼잡 제어와 흐름 제어를 가능하게 한다.
· 양방향 통신이다.
· connection-oriented 방식이다.
· 흐름 제어가 가능하다. sender가 receiver의 상황을 보고 window 사이즈를 조절한다.

TCP의 sequence number는 2개가 들어간다.
· 전형적인 sequence number
해당 패킷의 first byte가 들어간다.
· ACK 신호에 붙는 sequence number
상대편으로부터 올것이라고 예상되는 next byte가 들어간다.
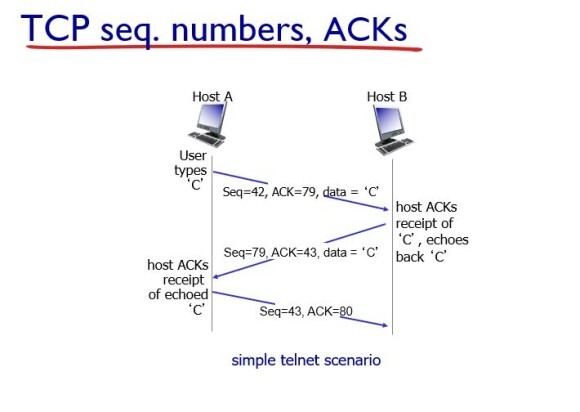
예를 들어, 처음에 Host A가 Seq # 42, ACK # 79, data ="C"를 보내면(seq는 해당 패킷의 first number, ACK신호는 내가 보낸 패킷이 제대로 보냈을 때 받을 거라 예상되는 번호), Host B는 그에 따라 ACK 신호로 받은 79를 seq #로 보내고 그 다음에 받을거라 예상되는 번호인 43을 보낸다(여기서 data가 C로 1바이트가 증가해서 42 + 1 = 43이 되었다. 만약의 "CB"처럼 2바이트 였으면 42 + 2 = 44이다). Host A는 다시 seq 43, ack 80 신호를 보낸다.

TCP에서는 RTT(Round Trip Time) 계산을 잘해야 한다. 이 RTT로 우리가 timeout을 정하기 때문이다. 이 timeout을 너무 짧게 잡으면 계속해서 중복전송이 일어나고, 너무 길게 잡으면 효율성이 떨어진다. 그래서 이 RTT를 가지고 timeout을 잘 정해야 한다.
그렇다면 RTT는 어떻게 정할까?
SampleRTT (내가 지금 샘플링한 RTT)를 활용해서 정한다.
그런데 SampleRTT는 편차가 굉장히 크다는 문제가 있다.
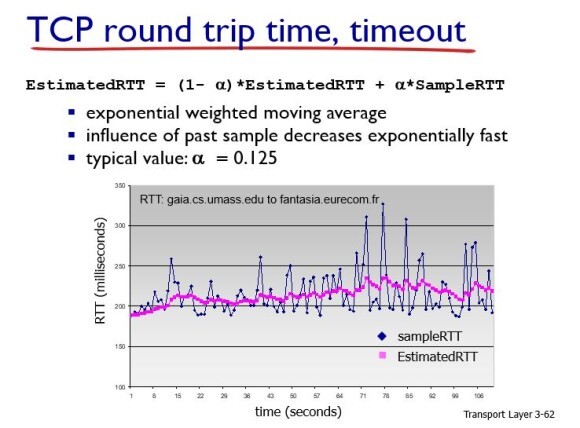
이 편차를 막기위해서 weighted moving average 기법을 사용한다. 즉
지금 측정한 값(SampleRTT)와 지금까지 측정된 값(EstimatedRTT)에 알파라는 가중치를 줘서 정한다.
그런데 일반적으로 알파를 0.125값으로 주는게 좋더라 라는 것이다.

그래서 최종적으로 timeout interval은 이 EstimatedRTT에 safety margin(timeout이 RTT보다 크도록 만들어주는 안전 마진)을 더해서 정한다.
이 safety margin은 DevRTT을 통해 결정되는데, DevRTT는 sampleRTT와 EstimatedRTT의 편차를 가지고 구한다.
여기서 베타 0.25와 DevRTT*4의 4는 통계적으로 가장 좋은 값이다.

위에서 설명했던 것들을 다시 정리해보자.
application layer로부터 데이터가 내려오면 이를 segment로 만들고 sequence number를 붙여준다.
sequence number는 해당 segment의 first data byte의 스트림 넘버가 들어간다.
Timer를 세팅해주고 timeout이 발생하면 다시 보내고 restart한다.
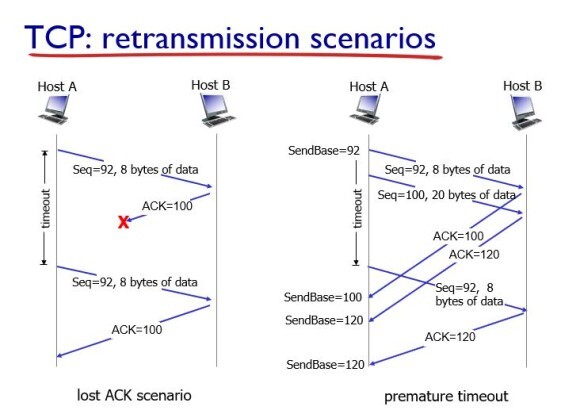
TCP가 재전송을 하는 시나리오들을 알아보자.
먼저 ACK 신호가 손실되는 시나리오를 봐보자.
Seq #가 92고 데이터가 8 바이트짜리 이므로 ACK 신호는 100이 되는데, 이 ACK 신호가 loss가 일어나면 Host A는 ACK 신호를 받지 못했으므로 해당 패킷을 다시 보낸다.
다음에는 premature timeout, 즉, timeout을 너무 짧게 설정하였을 때이다. 이 경우에는 패킷이 정상적으로 도착하였는데, ACK 신호가 우리가 정한 timeout보다 늦게 도착해서 해당 패킷을 다시 전송해서 duplicated가 발생한다.
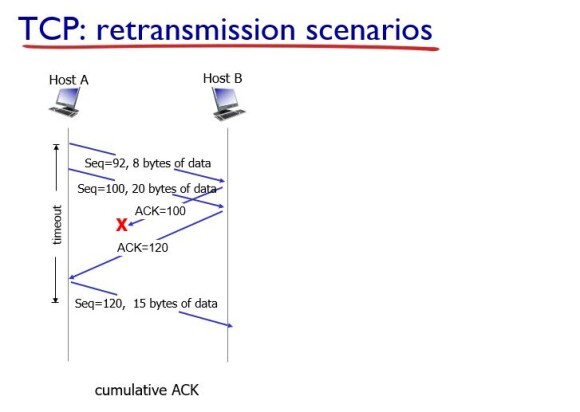
다음은 cumulative ACK이다.
이 상황은 조금 재밌는게 ACK 100은 loss가 일어나도 ACK 120이 무사히 도착하면 cumulative ACK 여서 첫번째 패킷(seq=92)도 무사히 들어갔다고 생각하고 패킷을 전송한다.

우리가 timeout을 정할 때, premature timeout이 발생하는 것을 방지하기 위해서 우리가 보수적으로 넉넉하게 시간을 잡았다.
그러다보니 성능이 좋을 때에는 timeout 될 때까지 기다리는 시간이 성능 저하의 원인이 된다.
그래서 등장한 것이 fast retransmit 기법이다.
fast retransmit은 timeout은 안됬지만, sender가 똑같은 데이터의 ACK를 3개 받으면 손실이 발생했다고 판단하고 재전송하는 방법이다.
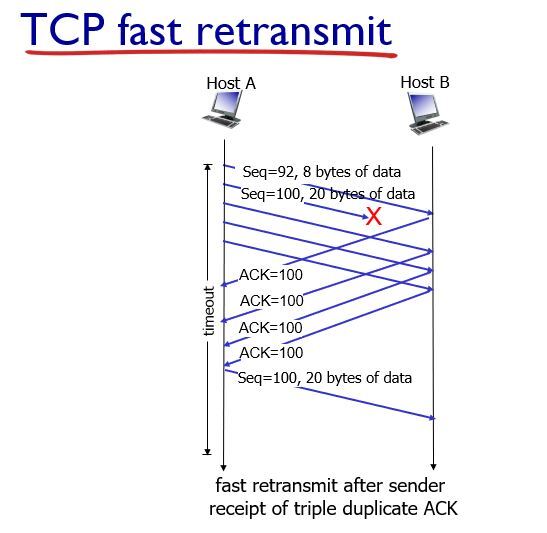
첫번째 패킷(seq=92)는 정상적으로 도착했지만 두번째 패킷(seq=100)에서 손실이 일어났다고 해보자. 그러면 Host B는 계속 첫번째 패킷의 대한 ACK 신호를 보낸다. 그러면 Host A는 timeout이 되지 않아도 2번째 패킷이 loss가 발생했다는 것을 알고 재전송을 하게 된다.
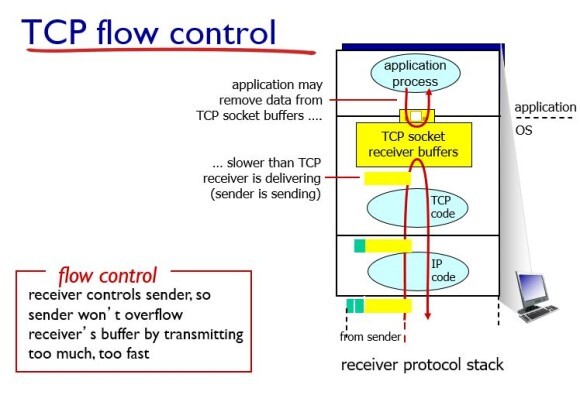
flow control의 동작 방법에 대해서 알아보자.
해당 그림이 Receiver 쪽이다. Application Layer는 소켓을 통해 버퍼에 있는 패킷을 가져오고 sender가 보낼 때 밑단에(datalink layer, network layer, transport layer) 각각 버퍼가 있어서 step by step으로 패킷을 가져온다.
이때, receiver가 sender에게 control을 알려준다.
(ex. receiver가 sender가 보내는 데이터양을 소화시키지 못하면 해당 사항을 sender쪽에 알려주면, sender가 그걸 알고 보내는 양을 조절해준다.)
그러면 그 정보를 어떻게 알려줄까?
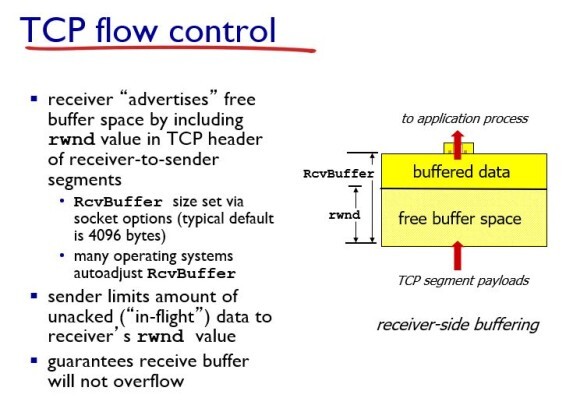
모든 receiver는 버퍼(buffer)를 가지고 있다.
이 버퍼의 사이즈를 RcvBuffer(Receive Buffer)라고 한다(일반적으로 4096 바이트로 디폴트 되어있는데, 요즘은 OS가 자동으로 해준다).
그러면 이 버퍼에 패킷이 버퍼링이 되는데(패킷이 쌓이게 되는데), 남은 버퍼링할 수 있는 영역(양)을 rwnd(receive window)라고 한다. 이 rwnd를 sender에게 알려준다.
그러면 sender는 받은 rwnd를 보고 보내는 패킷량을 조절한다. 그렇게 함으로써, 리시브 버퍼가 오버플로우가 일어나지 않도록 보장해준다.
'Study > 네트워크' 카테고리의 다른 글
| 4. Network Layer (Data Plane) (1) (6) | 2023.06.14 |
|---|---|
| 3. Transport Layer (3) (1) | 2023.06.14 |
| 3. Transport Layer (1) (0) | 2023.06.14 |
| 2. Application Layer (3) (0) | 2023.06.14 |
| 2. Application Layer (2) (0) | 2023.06.14 |