

3.1 Transport Layer Service
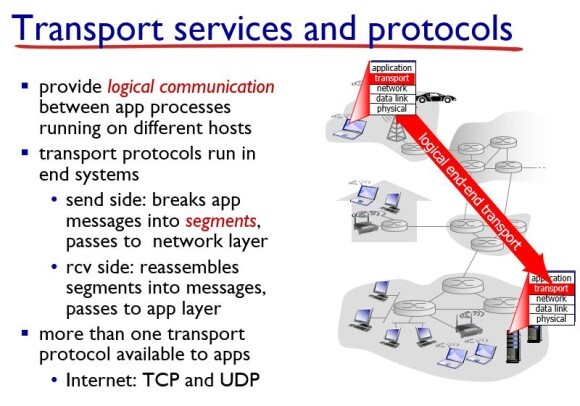
· Transport Layer의 역할은 서로 다른 호스트들에서 동작하는 어플리케이션 프로세스 간의 논리적 통신(Logical Communication)을 제공한다.
논리적 통신 : 어플리케이션 관점에서 봤을 때 프로세스들이 동작하는 호스트들이 직접 연결된 것처럼 보인다는 것을 의미
Transport 프로토콜은 end system에서 동작하는데 송신단과 수신단에서 다르게 동작한다.
송신단(Send Side) : application layer에서 생성된 message를 segment로 쪼개서 network layer로 보낸다.
수신단(Receive Side) : network layer에서 받은 segment들을 합쳐서(Reassemble) message로 만든 후, application layer로 보낸다.
이 transport layer에는 대표적으로 2가지의 프로토콜(TCP, UDP)이 존재한다.

TCP, UDP를 알아보기전에 network layer와 transport layer의 차이점을 먼저 알아보자.
두 계층의 공통점은 둘다 논리적 통신을 담당한다는 점이 있다.
하지만 transport layer는 프로세스 간의 논리적 통신을 담당하지만, network layer는 호스트 간의 논리적 통신을 담당한다는 차이가 있다.
여기서 프로세스란 구동 중인 프로그램을 의미한다.
즉, 네트워크 계층은 호스트 대 호스트 통신에만 책임이 있고, 목적지 컴퓨터에게만 메시지를 전송한다. 하지만 이것만으로는 전송이 완료되었다고 할 수 없다. 메시지를 올바른 프로세스를 통해 처리하여 상위 또는 하위 계층으로 전달해야 한다. 이것이 바로 transport layer protocol이 수행해야 할 책임이다.

자 그럼 transport layer의 대표적인 프로토콜인 TCP(Transmission Control Protocol)와 UDP(User Datagram Protocol)을 알아보자.
TCP는 혼잡 제어(Congestion Control)과 흐름 제어(Flow Control)이 가능한 프로토콜이다. connection setup을 통해서 통신이 일어난다.
반면에 UDP는 신뢰성을 보장하지 않지만 TCP보다 빠르게 동작할 수 있다는 장점이 있다.
이 2가지 프로토콜의 공통점은 delay guarantee와 bandwidth guarantee가 안된다는 점이 있다. 이유는 둘다 패킷 스위칭 기법을 사용하기 때문이다.
3.2 멀티플렉싱, 디멀티플렉싱

가운데에 서버가 있고 양쪽에 클라이언트가 있다고 해보자. 하나의 머신에서 여러 개의 프로세스들이 존재하고 개별 프로세스들이 다른 머신과 네트워킹을 하기 위해선 하나의 통로를 거치는 과정이다.
서버가 다수의 클라이언트에게 데이터를 보낼 때(서버가 sender 일 때)는 각 프로세스가 각자의 소켓을 통해 메시지를 보내고 TCP 혹은 UDP를 통해서 멀티플렉싱을 해서 메시지를 세그먼트로 나누고 추가적인 정보(포트 넘버)를 넣는다.
반대로 서버가 다수의 클라이언트에게 데이터를 받을 때(서버가 receiver일 때)는 디멀티플렉싱을 해줘야 한다.
멀티플렉싱은 메시지에서 세그먼트로 쪼개고 header에 목적지에 대한 port number를 입력한다.

멀티플렉싱과 디멀티플렉싱은 어떻게 가능할까? 바로 포트 넘버를 사용하기 때문에 가능하다. 위 사진에서 application data(payload)가 바로 메시지다. 앞에서 설명했듯 이 메시지가 세그먼트로 쪼개진 뒤에 header라는 정보가 추가로 붙는데 그 중에서 가장 중요한 것이 Port number 이다.
이 포트 넘버가 첨가된 것이 바로 세그먼트이고 여기에 IP address가 추가로 붙는 것이 datagram이다.
그래서 호스트는 포트 번호와 IP 주소를 가지고 적절한 소켓으로 전달한다.

TCP 소켓에는 4가지의 tuple이 존재한다.
· Souce IP address
· Souce port number
· Destination IP address
· Destination port number
수신자는 이 4개의 information tuple을 가지고 세그먼트들을 적절한 소켓에 넣어준다.
이 4개의 튜플은 동일할 수가 없기 때문에 서버는 여러개의 프로세스를 동시에 처리할 수 있다.
3.3 Connectionless transport: UDP

UDP는 네트워크 송수신 시 송신자가 수신자에게 일방적으로 데이터그램을 전송하는 통신 방식으로 최소한의 필요한 기능만 수행한다.(IP에 포트 지정 가능)
packet lost가 일어날 수 있고, 메시지가 뒤섞여서 들어온다.
또한 비연결성(connectionless)으로, 단순히 데이터를 던진다.
즉, 오류는 검출하지만 복구나 재전송이 없고, congestion control이나 flow control을 수행하지 않는다.
구조가 단순한 만큼 속도가 빨라 스트리밍 서비스에 사용된다.

UDP 세그먼트는 위 사진과 같은 형태를 띄는데, 앞서 설명드렸다시피 application data인 message에 헤더가 붙어서 세그먼트가 되는데 가장 중요한 정보가 포트 넘버이다. 그 다음 중요한 것이 checksum이다. 여기서 checksum은 에러 체크를 할 때 사용된다.
UDP는 아주 단순하고 header 사이즈가 작기 때문에 용량이 작고 빠르게 전송할 수 있다는 장점이 있다.
3.4 Principles of reliable data transfer

네트워크에서 중요한 토픽 10개가 있는데 그 중에 항상 들어가는 요소가 바로 신뢰성(Reliability) 이다.
신뢰성이란 네트워크에서 링크 실패 등이 일어났을 경우에도 사용자가 이것을 느끼지 못하도록 서비스를 계속할 수 있는 능력을 말한다.
신뢰성을 보장하는 층은 transport layer와 datalink layer가 있는데 여기서는 transport layer만 보자.
Application layer에서 바라봤을 때 자기 밑에 있는 Transport layer는 신뢰성이 있는 채널이라고 생각한다. 그런데 transport layer 관점에서 봤을 때에는 application layer로부터 메시지를 받으면 이것을 세그먼트로 만들어서 network layer로 내려 보내야 하는데, 이 network layer는 unreliable한 채널이라고 생각한다.

Reliable data transfer 과정을 자세하게 알아보자.
Application Layer에서는 rdt_send(reliable data transfer) 라는 함수를 통해 메시지를 transport layer로 보낸다. 그러면 transport layer에서는 해당 메시지에 header 파일에 포트 넘버를 넣고 세그먼트를 만든다. 그 뒤, udt(unreliable data transfer)_send 함수를 통해 밑의 계층(unreliable한 채널)로 보낸다.
수신측에서는 rdt_rcv 함수를 통해 패킷을 받아들인다. 그런데 unreliable한 채널에게 패킷을 받아드리므로 이 패킷이 오류가 없는지 체크를 해야한다. 체크를 하고 문제가 없으면 최종적으로 deliver_data 함수를 통해 세그먼트를 메시지로 만들어서 application layer로 올려준다.
이해를 돕기위해 rdt를 우리가 한번 만들어보자.

먼저 가장 기본적으로 동작하는 rdt 1.0부터 봐보자.
가장 완벽한 채널(어떤 비트 에러도 없고, 패킷 손실도 없는)을 가정해보자.
그러면 송신측에서는 위(application layer)로부터 기다리는 state만 있으면 되고, 수신측에서도 아래(network layer, 등등)로부터 기다리는 state만 있으면 된다.
송신측에서 rdt send가 일어나면(event) 데이터를 세그먼트로 만들고 udt_send 함수를 실행하는 액션을 취하면 된다. 수신측에서는 rdt_rcv 함수가 일어나면 세그먼트에서 페이로드 부분을 추출해서 메시지로 만든 후, deliver_data 함수를 실행하는 액션을 취한다.

rdt 1.0은 너무 이상적인 환경이어서 간단하였으니, 그보다 조금 더 현실적인 상황을 가정해보자. bit error가 있는 상황. 즉, 비트 에러를 검출하기 위해 체크썸을 해서 reliability를 보장하는 상황을 가정해보자.

체크썸을 통해 에러를 검출했으면, 이 에러로부터 회복하기 위해서 ACKs(acknowledgements)와 NAKs(negative acknowledgements)를 사용한다.
수신자가 패킷을 받고 만약 애러가 검출되지 않으면(정확하면) ACK 메시지를, 검출되면 NAK 메시지를 보낸다.
즉, rdt 2.0은 error detection을 해주고, control message(ACK, NAK)을 통해서 sender 쪽에 알려준다.
이를 FSM으로 봐보자.

보면 1.0에 비해서 sender 쪽에 state가 하나 늘어났다.
1.0과 마찬가지로 위에서 메시지가 올때까지 기다렸다가 rdt_send 함수를 실행하고 패킷을 보내면 receiver 쪽에서 ACK 메시지나 NAK 메시지가 올때까지 기다린다.
receiver 쪽에서는 패킷을 받아서 에러가 검출되면 NAK 메시지를 sender에게 보내고, 검출되지 않으면 ACK 메시지를 sender에게 보내고 세그먼트를 메시지로 만들어서 application layer로 보낸다.
ACK 신호를 보내면 sender에 state는 다시 어플리케이션으로부터 메시지를 기다리는 state로 바뀐다.

그런데 rdt 2.0에는 치명적인 문제가 존재한다.
바로 ACK/NAK 메시지가 오류가 발생하거나 손실될 수 있다.
예를 들어, 수신 측에서 패킷에 오류를 탐지하고 NAK 메시지를 보냈는데, 이것이 손실될 수 있다. 이러면 수신 측은 무한정으로 ACK or NAK 메시지가 오는 것을 기다리게 된다. 혹은 ACK/NAK 신호가 중복으로 발생해서 패킷 재전송을 중복으로 전송할 수도 있다.
이 문제를 해결하기 위해 ACK과 NAK 신호에도 sequence number를 붙여준다.
그래서 나온 것이 rdt 2.1이다.


rdt 2.1은 패킷이 나갈 때, 그 패킷의 고유한 sequence number를 부여해주는 것이다.
sender는 패킷에 시퀀스 넘버를 붙여준다. 이 시퀀스 넘버는 여러개 할 필요없이 0, 1로만 해도 충분하다.
그리고 ACK과 NAK 신호가 문제가 없는지 확인한다.
receiver 쪽에서는 받은 패킷이 중복된 것인지 아닌지 확인한다.


rdt 2.0에서 2.1로 복잡하게 올라갔는데 이를 좀더 심플하게 만들어보자.
rdt 2.2에서는 NAK 신호가 필요가 없다. ACK 신호 하나만으로 NAK 신호까지 구현해 낼 수 있다.
바로 동일한 패킷 넘버의 ACK 신호를 한번 더 보내준다. 똑같은 ACK 신호가 동시에 똑같은 시퀀스 번호로 온다면 받는 쪽에서는 이것이 NAK 신호가 온 것과 동일하다라고 인식하게 만든다.

이번에는 에러뿐만 아니라 패킷 손실까지 고려해보자.
sequence number와 Timer 를 사용한다.

(a) 패킷 손실이 없으면 그냥 정상적으로 sender가 패킷(+시퀀스 넘버)을 보내고 receiver가 ACK(+시퀀스 넘버) 메시지를 보낸다.
(b) 만약에 sender 가 패킷을 보냈는데 패킷 손실이 일어나면 어떻게 될까? receiver가 그에 해당하는 ACK 신호를 보내지 않을 것이고 sender는 특정 시간동안 ACK 신호가 오지 않으면 패킷 손실이 일어낫다고 판단하고 다시 해당 패킷을 보낸다.

(c) 만약 ACK 신호가 손실되면 어떻게 될까?
b에서와 마찬가지로 sender는 전송한 패킷에 대한 ACK 신호를 받지 못해 다시 해당 패킷을 보내게 되고, receiver는 받은 패킷이 중복해서 들어왔으므로 ACK 신호에 손실이 일어낫다고 판단하여 다시 해당 패킷의 ACK 신호를 보내게 된다.
(d) 만약 우리가 timeout을 너무 짧게 설정하면 ACK 신호가 sender에게 도착하기 전에 timeout되서 위 사진과 같이 계속해서 duplicate가 발생하게 된다. 이를 막기 위해서 마진을 둬서 이런 일이 발생하지 않게 만든다.

자 그런데 지금까지의 방식들은 신뢰성들은 보장했지만 효율성은 처참했다.
하나의 패킷을 보내면 해당 RTT 동안 그냥 놀게 되는 것이다. 이 문제를 해결해 효율성을 늘리기 위해서 등장한 것이 파이프라이닝(Pipelining)이다.

파이프라이닝이란 하나의 패킷을 보내고 기다리는 것이 아니라 여러개 패킷들을 보내고 기다리자는 것이다.
이 파이프라인 프로토콜을 구현하는 방법은 2가지가 있다.
· go-Back-N
· selective repeat

rdt 3.0에서 효용성이 0.00027 이였지만, 파이프라이닝을 사용하면 해당 패킷의 갯수 만큼의 효율이 증가하게 된다.

앞서 설명했다 시미 pipelined protocol을 구현하는데에는 2가지 방법이 있다.
일단 두 방법 모두 sender가 N개의 패킷을 파이프라인으로 넣는다.
· Go-back-N
receiver가 cumulative ACK 를 보낸다. 즉, sender가 receiver에게 ACK 신호 하나를 받으면 이 이전까지의 패킷은 모두 success 하다라는 것을 의미한다.
그렇기 때문에 타이머가 하나만 있어도 된다.
하지만, 어떤 ACK 신호 하나가 날아가면 멀쩡히 받은 패킷도 중복 전송이 된다는 문제점이 있다.
· Selective Repeat
패킷 하나하나 당 하나의 타이머를 둔다. 그리고 각 패킷에 개별적인 ACK 신호를 준다.
그렇기 때문에 중복 전송이 발생하지 않는다는 장점이 있지만, 타이머가 많이 필요하다라는 단점이 있다.

GBN 프로토콜에서 sender는 ACK 을 기다리지 않고 여러 패킷을 전송할 수 있지만 파이프라인에서 ACK 을 받지 않은 패킷의 최대 허용 갯수는 N보다 크지 않아야 한다. 그리고 노란색(전송했지만 아직 ACK 신호를 받지 않은 패킷)에서 ACK 신호를 받으면 녹색으로 처리하고 윈도우를 해당 갯수 만큼 이동시킨다.

receiver 쪽에서는 올바르게 받은 패킷 중 가장 높은 시퀀스 번호(즉, 가장 최근에 올바르게 받은)의 ACK 신호를 보낸다.
그렇기 때문에 ACK 신호가 중복으로 발생할 수 있다. 그리고 receiver는 expected sequence number가 필요하다.

예를 들어, 0 1 2 3 패킷이 동시에 전송이 됬는데 2번 패킷에서 loss가 일어났다. 그러면 receiver는 2번 패킷이 와야 되는데 3번 패킷을 받았으므로 손실이 일어났다고 판단하여 가장 최근에 정확히 받은 패킷인 ack 1 신호를 다시 sender에게 전송한다. sender는 재전송 된 ack1 신호를 받은 이후의 ack 신호는 무시하고 다시 2번 패킷부터 재전송한다.

Selective repeat에서 타이머가 패킷마다 존재한다. receiver는 버퍼를 가지고 있어서 reordering을 한다. 그래서 받은 패킷을 버리지 않는다. 순서가 맞지 않으면 reordering을 통해 순서를 다시 맞춘다.
'Study > 네트워크' 카테고리의 다른 글
| 3. Transport Layer (3) (1) | 2023.06.14 |
|---|---|
| 3. Transport Layer (2) (0) | 2023.06.14 |
| 2. Application Layer (3) (0) | 2023.06.14 |
| 2. Application Layer (2) (0) | 2023.06.14 |
| 2. Application Layer (1) (0) | 2023.06.14 |