

3.6 principle of congestion control

congestion contol은 수신단도 받을 능력이 있고, 송신단도 보낼 충분한 능력이 있는데 보내는 관에 문제가 발생한 것이다.
congestion이란 너무나 많은 소스가 너무나 많은 데이터를 너무 빨리 보내기 때문에 네트워크가 다운이 되버리는 것이다.
congestion이 일어났다는 것은 패킷 로스가 일어나거나(라우터에서 발생) 너무 딜레이가 길어지면(timeout 발생, 패킷 로스가 일어나면 버퍼가 꽉 찬것이므로 큐잉 딜레이가 맥시멈으로 발생)하면 알 수 있다.
다음으로 congestion이 일어나는 시나리오들을 봐보자.
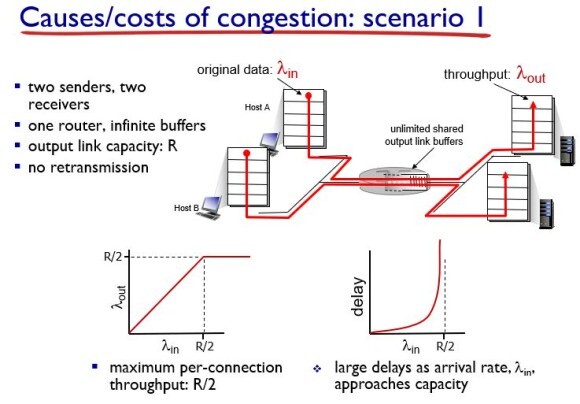
먼저 2개의 sender와 receiver가 있고 하나의 라우터를 통하는데 이 라우터는 무제한 사이즈를 갖는 버퍼가 있다고 해보자(retransmission이 없다).
이런 상황에서는 input과 output이 정확히 일치한다(throughput과 goodput이 동일하다).
여기서 goodput이란 리시버가 받은 전체 데이터 중에서 중복된 패킷을 뺀 값이다.
즉, 이런 상황에서는 throughput = goodput 이 된다.
하지만 버퍼가 무한데로 패킷을 쌓을 수 있기 때문에 딜레이가 무한대로 간다.
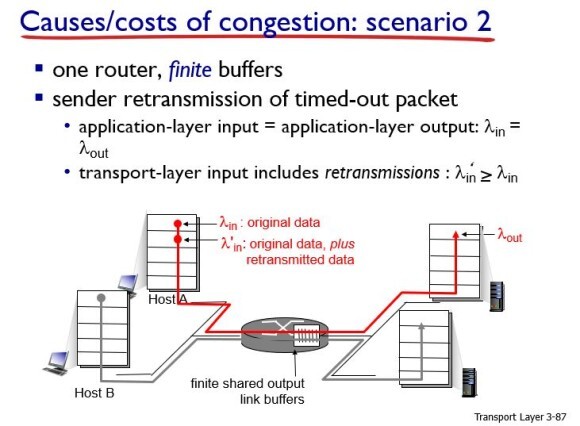
두번째 케이스는 사이즈에 제한이 있는 버퍼가 있는 경우이다. 즉, 패킷 손실이 발생할 수 있는 경우이다.
이 경우 application layer에서의 input보다 transport layer의 input이 더 많다. 왜냐하면 패킷 손실이 일어나서 재전송하는 경우가 발생할 수 있기 때문이다.
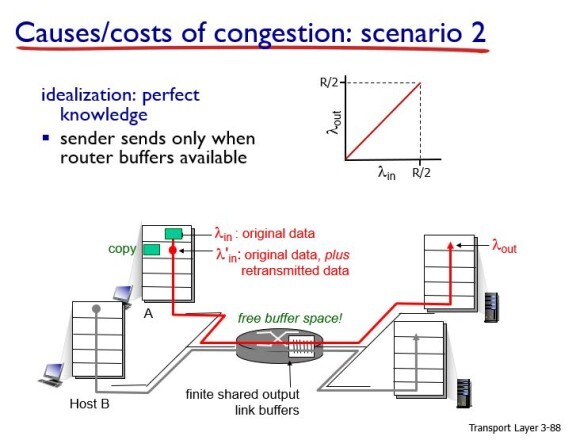
만약 패킷 손실이 발생하지 않고 잘 가게되면 이전 시나리오와 마찬가지로 input, output이 1이 된다(throughput = goodput).
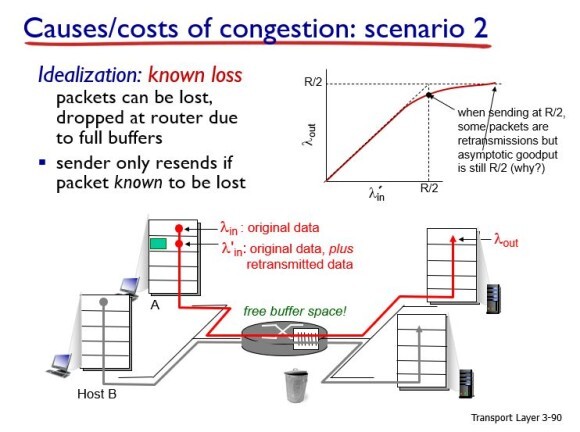
하지만 패킷 손실이 일어나서 재전송을 하게 되면 실제 보낸 량보다 리시버가 받아드린 양이 조금 적다(goodput < throughput). 그러나 시간이 지나면 궁극적으로는 같아진다.
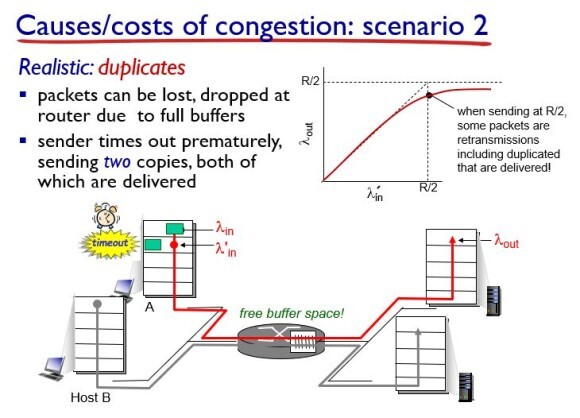
그러나 만약의 duplicate가 발생하면(패킷을 보냈는데, timeout이 발생해서 receiver단에 동일한 패킷이 중복해서 도착했을 때) input과 output값이 영원히 같아질 수 없다. 왜냐하면 동일한 패킷이 도착했으므로 하나는 버려야 하기 때문에 application layer에서 보았을 때 그만큼 낭비가 된 것이다.
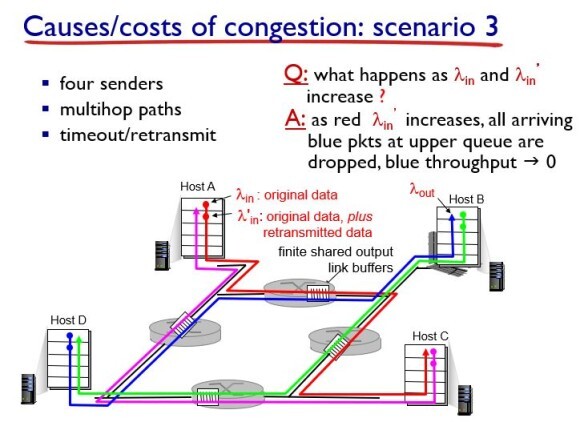
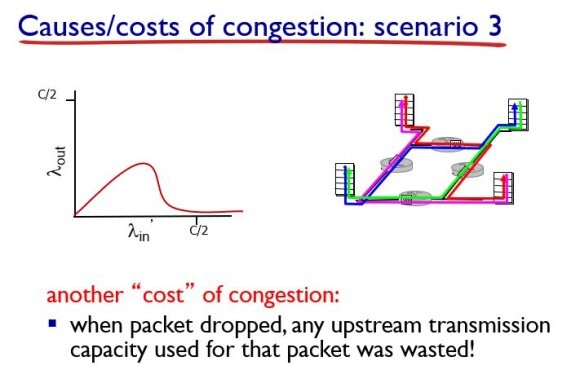
마지막 3번째 시나리오는 라우터의 버퍼가 서로 다른 커넥션을 품고 있는 경우이다. 빨간색과 파란색 링크를 품고 있는 라우터를 봐보자.
빨간 애가 패킷 생산을 늘린다. 그러면 라우터는 누가 보낸 패킷인지 모르니까 오는 데로 처리를 해준다. 그러면 파란 애는 일반적으로 보내고 있었데 해당 라우터의 버퍼가 꽉 차서 큐잉 딜레이가 커지고 패킷 손실이 일어나서 파란 애의 throughput은 0이 되버린다.
이러한 문제들을 막기 위해 TCP congestion control이 필요하다.
3.7 TCP congestion control
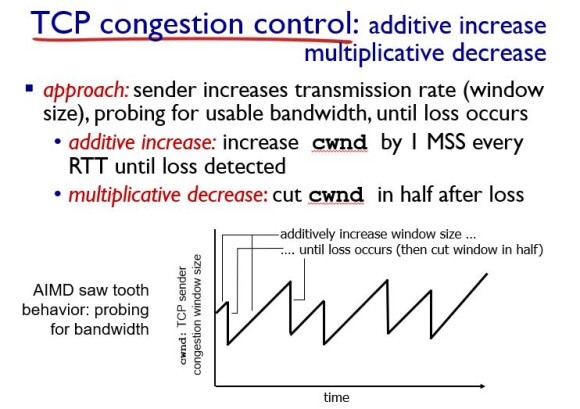
AIMD(Additive Increase Multiplicative Decrease)
순차적으로 증가되고 와장창 깎아라.
sender 입장에서는 현재 congestion이 일어났는지 알 수 없으므로 패킷을 보내는 량(전송 속도 즉, window size)을 1 MSS(Maximum Segment Size)씩 증가시켜서 보낸다.
그러다가 손실이 발생하면 이 congestion window 사이즈를 반으로 줄인다.
그리고 다시 그 반으로 준 사이즈에서 1씩 증가시킨다.
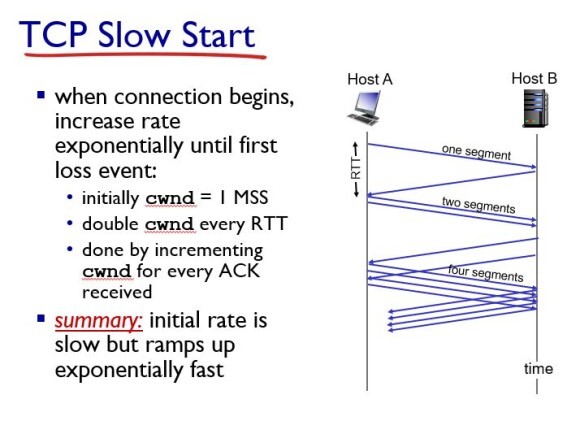
Slow Start는 맨 처음의 cwnd를 1 MSS 에서 시작해서 loss가 발생할 때까지 1RTT당 2배씩 증가시키는 것이다. 그리고 loss가 발생하면 다시 이 cwnd를 1MSS로 줄인다.
그런데 손실이 일어났다고 다시 1부터 다시 시작하는 것은 너무 가혹하다. 그러므로 1부터 하지말고 반으로 줄이자라고 한것이 TCP RENO다.

TCP tahoe의 경우에는 시작할 때에는 Slow Start와 마찬가지로 cwnd를 1MSS로 셋팅한다.
그 다음 cwnd 사이즈를 2배씩 증가시키는데, 이 사이즈를 무한대로 증가시키면 최후에는.....(loss)
이 문제를 막기 위해 임계값(Threshold)를 둔다.
이 임계값은 바로 바로 직전에 패킷 손실이 일어났을 때의 cwnd의 반을 임계값으로 둔다. 그리고 임계값에 도달할 때 까지는 2배씩 증가하고 임계값에 도달하면 1MSS 씩 증가하도록 설정하는 것이다.
참고로 loss가 발생하면 cwnd는 다시 1부터 시작한다.
TCP RENO의 경우에는 처음 시작할 때에는 1MSS부터 시작한다. 단 tahoe와의 차이점은 3 duplicate ACKs 신호를 받으면(loss 발생) cwnd를 1MSS부터 시작하지말고 loss가 발생했을 때의 절반 값에서 시작하고 linear하게(1MSS 씩) 증가시키는 것이다.

그림으로 보면 위와 같다.
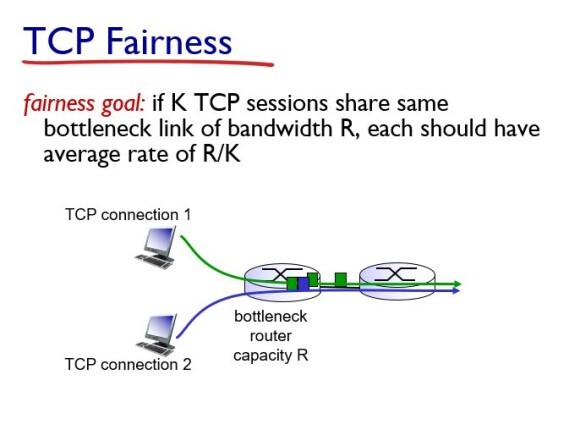
네트워크에서 항상 고려해야되는 요소가 2개 있다.
· 효율성(Efficiency)
· 공평성(Fairness)
효율성은 간단하다 파레토 최적(Pareto Optimal)만 보장하면 된다.(파레토 최적은 게임 이론 참조, 쉽게 말해서 자원을 전부 다 사용하는 것이다. 즉, 자원 사용량이 boundary set에 도달)
그런데 공평성은 보는 관점에 따라서 다 다르게 정의한다.
공평성이란 throughput을 결정하는 bottleneck에서 bandwidth를 얼마나 공정하게 share하고 있는가를 나타낸다.
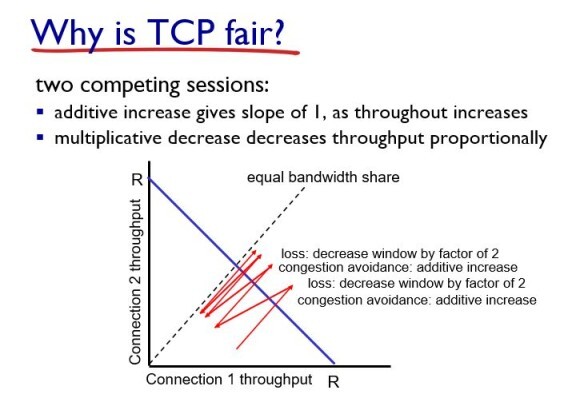
여기서는 Egalitarian 으로 예를 들어보자.
x축이 connection 1, y축이 connection 2의 throughput라고 해보자.
처음에 증가하다가 loss가 발생하면 cwnd를 반토막을 내버린다. 그리고 다시 증가하는 과정을 반복한다. 그러면 최종적으로 50% 씩 나누게 된다.
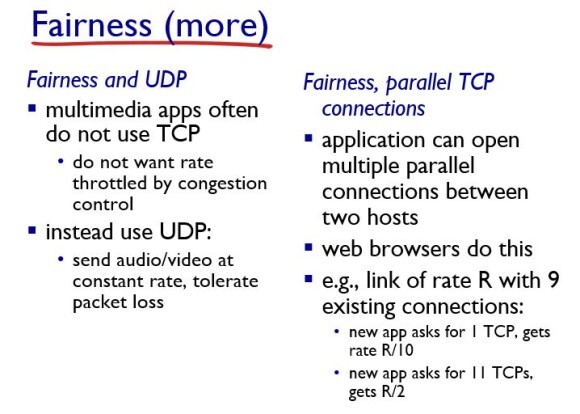
그런데 parallel TCP connections의 경우 application이 여러개의 parallel connection을 사용하는데 어떤 app은 1개의 tcp 커넥션을 쓰고 어떤 애는 11개의 tcp 커넥션을 사용하면, application의 관점에서보면 fairness가 잘 안맞는다.
UDP는 애초에 Fairness의 개념이 없다.
'Study > 네트워크' 카테고리의 다른 글
| 4. Network Layer (Data Plane) (2) (1) | 2023.06.14 |
|---|---|
| 4. Network Layer (Data Plane) (1) (6) | 2023.06.14 |
| 3. Transport Layer (2) (0) | 2023.06.14 |
| 3. Transport Layer (1) (0) | 2023.06.14 |
| 2. Application Layer (3) (0) | 2023.06.14 |